Unreal Speech
Unreal Speech is an innovative text-to-speech service designed to offer a cost-effective solution in the realm of digital speech synthesis. It stands out in the market for its ability to …
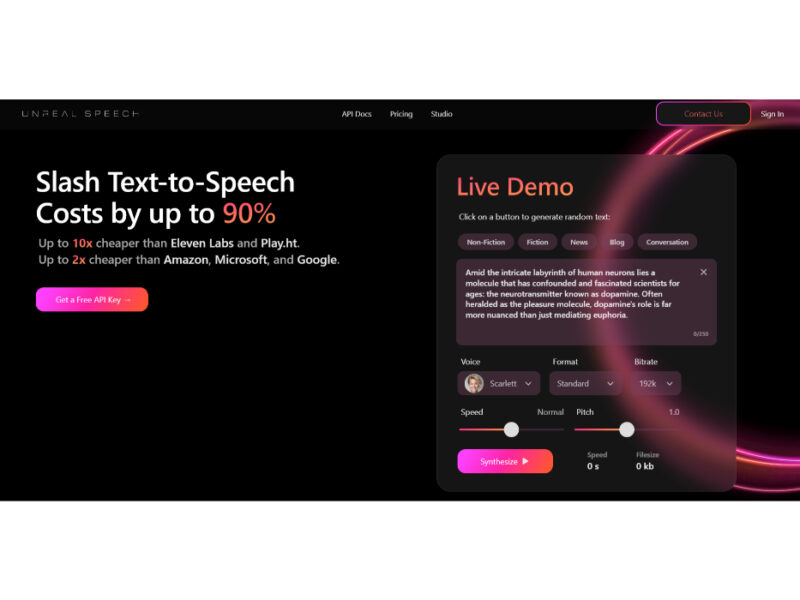
About Unreal Speech
Use Cases
Use Case 1: High-Volume Audiobook and Textbook Conversion
Problem: Digital publishers and educational platforms often struggle with the high cost and slow processing times associated with converting large libraries of text (like 500-page textbooks or long-form fiction) into audio format. Competitors like Eleven Labs can become prohibitively expensive at the scale of millions of characters.
Solution: Unreal Speech is designed for high-volume tasks, offering a /synthesisTasks endpoint that handles up to 500,000 characters per request at a cost 11x cheaper than leading competitors. Its ability to process 10,000+ pages per hour makes it a viable solution for mass-scale content migration.
Example: A university library uses the Python SDK to batch-process 2,000 academic journals into MP3 files, allowing students to listen to research papers on the go while saving 75% on API costs compared to their previous provider.
Use Case 2: Interactive Language Learning and Literacy Apps
Problem: For children or language learners, hearing audio isn't enough; they need to see the connection between the spoken word and the written text. Synchronizing UI highlights with audio manually is incredibly time-consuming for developers.
Solution: The API provides per-word and per-sentence timestamps via a WebSocket connection (/streamWithTimestamps). This allows developers to receive real-time data on exactly when each word is spoken, enabling "karaoke-style" text highlighting.
Example: An ed-tech startup builds a "Read Along" feature for their mobile app. As the "Scarlett" voice reads a story, the app uses the start and end JSON timestamp data to highlight each word in blue, helping the student follow the phonetic structure of the sentence in real-time.
Use Case 3: Low-Latency AI Voice Assistants
Problem: In conversational AI, "latency" (the delay between a user asking a question and the AI responding) is the biggest barrier to a natural experience. Most TTS engines take 1–2 seconds to generate audio, which creates an awkward silence.
Solution: Unreal Speech offers a /stream endpoint with a 300ms latency. This "instant-response" capability allows for near-human conversational speeds, making it ideal for integration with LLMs (like GPT-4) for voice-based customer support or virtual companions.
Example: A travel agency implements a React Native-based AI assistant. When a customer asks about flight status, the app sends the LLM's text response to the Unreal Speech /stream endpoint, and the audio begins playing almost the moment the text is generated, creating a fluid conversation.
Use Case 4: Automated News and Blog Narration for "Listen-Later" Services
Problem: Content creators and news outlets want to offer "Listen to this article" features to increase engagement, but the high volume of daily posts makes manual recording impossible and high-end API costs unsustainable for ad-supported sites.
Solution: By using the /speech endpoint, developers can automatically generate high-quality audio for every new blog post or news update. The API's ability to adjust speed and pitch allows the outlet to create a specific "brand voice" that remains consistent across all articles.
Example: A tech news site integrates the Node.js SDK into their CMS. Every time an editor hits "Publish," the system automatically generates an MP3 version of the article using the "Dan" voice at 1.1x speed. This audio is then embedded at the top of the post, allowing commuters to consume the news via a professional-sounding narration.
Key Features
- Ultra-low cost TTS API
- Sub-300ms audio streaming latency
- Synchronized per-word timestamp generation
- Long-form audio synthesis support
- High-volume batch processing capabilities
- WebSocket-based real-time audio streaming
- Customizable audio parameter controls
Similar Tools You Might Like
Discover more tools in the same category
Hypotenuse ai
Hypotenuse AI is a state-of-the-art AI Writing Assistant and Text Generator designed to streamline and …
Explore Related Categories
Live Preview:
Updates automatically with live stats
Copied to clipboard!